Hogyan építkeznek a nagyok? 1. rész - Facebook


Legújabb sorozatunkban az internet legnagyobb, és legismertebb oldalainak felépítését fogjuk boncolgatni. Milyen technológiával, hogyan, és mennyi embert szolgálnak ki napról-napra? Milyen nehézségekkel kellett szembenézniük a szakembereknek a fejlesztések során? Igyekszünk mindenre választ adni úgy, hogy az adott területen kevésbé jártasak számára is feltáruljanak a titkok.
Első részünkben a Facebook-ot vesszük szemügyre.
Kezdjük egy gyors statisztikai áttekintéssel, hogy mindenki képbe kerüljön, mekkora adatmennyiséget kell kezelnie a Facebook mögött található informatikai rendszereknek:
- 1 milliárd 310 millió felhasználója volt 2014. január 1-én
- Mobilon 680 millióan használják
- Naponta több, mint 500 terabájtnyi új adat kerül be az adatbázisokba
- Több, mint 100 petabájtnyi adatot tárolnak egy HDFS fájlrendszer segítségével
- Havonta összesen 640 millió percet töltenek az emberek a Facebook-on
- Minden 20 percben megosztanak 1 millió linket, küldenek 2 millió felkérést (Friend request), és 3 millió üzenetet
Meglepő lehet, de a Facebook megjelenítéséért egy LAMP-alapú megoldás felel. A HTTP szerver szerepét tehát a Linuxon futó Apache tölti be, az adatokat MySQL adatbázisokban tárolják, és maga az alkalmazás PHP nyelven íródott.
Linux, Apache
A Linux ingyenes, nyílt forráskódú, rendkívüli módon testreszabható, és biztonság szempontjából is jó választás. Az Apache szintén ingyenes, és nyílt szoftver, így ez a páros majdnem vitathatatlan választás.
MySQL
Itt már páran valószínűleg ráncolják a homlokukat... A MySQL-t ritkán alkalmazzák ekkora méretű adatbázisoknál, a Facebook mégis mellette tette le a voksát. Ehhez tudni kell, hogy nem is feltétlenül a szokványos módon "használják": az adatokat elsősorban a NoSQL megoldásokból ismert kulcs-érték formában tárolják adatbázisok tömkelegén, ezek az adatbázisok pedig fizikai csomópontokon vannak szétszórva (ezek menedzselésében segít a Cassandra), és ezen a szinten valósul meg a terhelés elosztása is.
Mindehhez társul egy saját fejlesztésű partícionálási módszer is, aminek keretében minden tárolt adat kap egy globális ID-t. Az archiválást is testreszabták, ami főként azon alapul, hogy az egyes felhasználók a tartalmaikat milyen gyakran, és milyen időrendben szokták "lekérni".

PHP
A PHP sem feltétlenül optimális választás igazán nagy webes megoldásokhoz, mert nehezen skálázható. Ugyanakkor igen elterjedt, aktív közösséggel rendelkezik, és hozzáértő fejlesztők kezei alatt igényesen és gyorsan is lehet vele fejleszteni.
Mike Schroepfer, a Facebook alelnöke egy korábbi interjúban erre reagálva elmondta, hogy "Bármilyen weboldal skálázása kihívást jelent, egy közösségi oldalé viszont különleges kihívást".
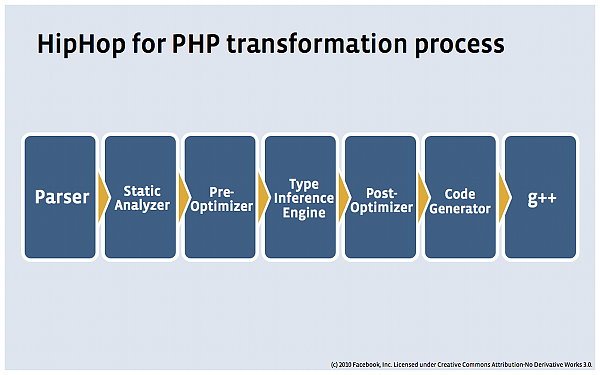
A PHP hátrányait kiküszöbölendő, a Facebook fejlesztői létrehoztak egy HipHop névre hallgató fordítót, amely a PHP kódot C++ nyelvre fordítja, majd ebből pedig gépi kódot generál, jelentősen optimálisabbá téve ezzel az erőforrások kihasználását. Ehhez kapcsolódóan a Facebook kicsit "továbbfejlesztette" a PHP-t is, bevezette a típusokat, és elnevezte az egészet Hack-nek, amit sok helyen már a PHP jövőjével azonosítanak.
Memcache
A tervezés és a fejlesztés során kihagyhatatlan volt valamilyen gyorsítótárazási technológia bevetése. A Facebook-nál erre a célra a Memcache-t választották, ami a fenti szoftverekhez hasonlóan nyílt forráskódú, és ingyenes. Az adatokat és az objektumokat a memóriában tárolja, ezzel drasztikusan növelve azok elérésének sebességét, illetve csökkentve az adatbázisok terhelését.
A Memcache sebességét talán a következő esettel lehet a legjobban érzékeltetni: az idővonalunk (News Feed) megtekintésekor, miután a Multifeed nevű, saját fejlesztésű algoritmus kiválasztotta a megjelenítendő bejegyzéseket, a Memcache-nek másodpercenként 50 millió műveletet kell végrehajtania, és ebbe beletartozik a fotók lekérése is, 1.2 millió fotó / másodperc sebességgel.
Sorozatunk következő részében a Google jön...